Dinky
Dinky 为 Apache Flink 而生,让 Flink SQL 纵享丝滑
为 Apache Flink 深度定制的新一代实时计算平台,
提供敏捷的 Flink SQL 作业开发、部署及监控能力,助力实时计算高效应用。
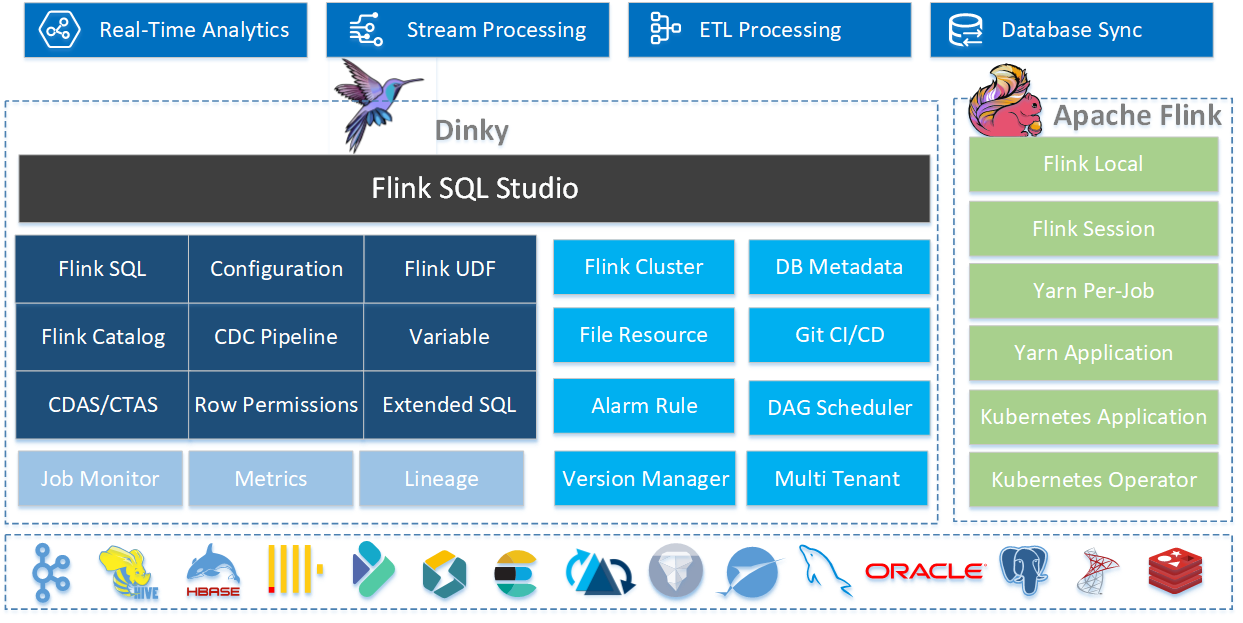
Dinky Core Features
快速开发
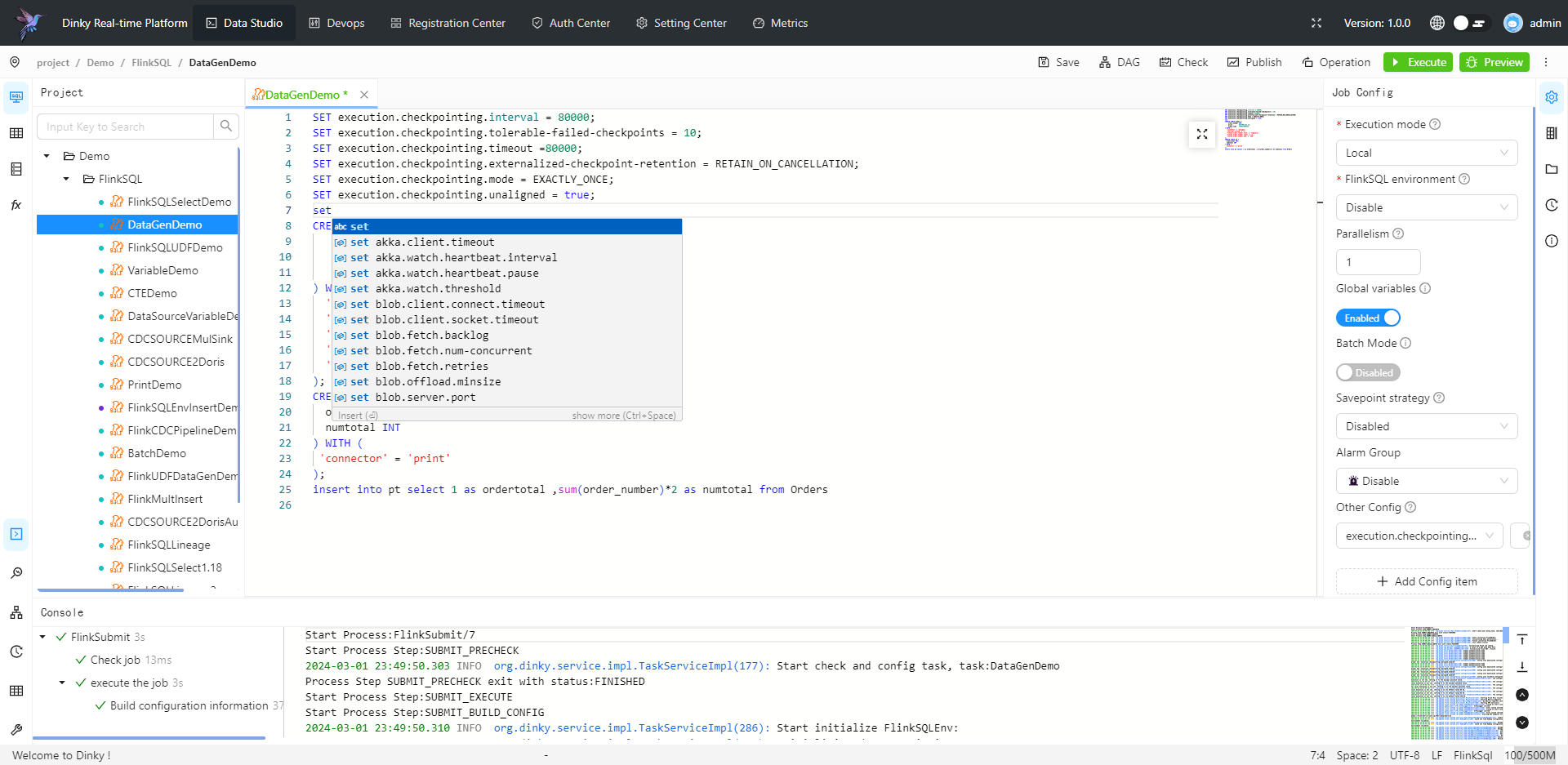
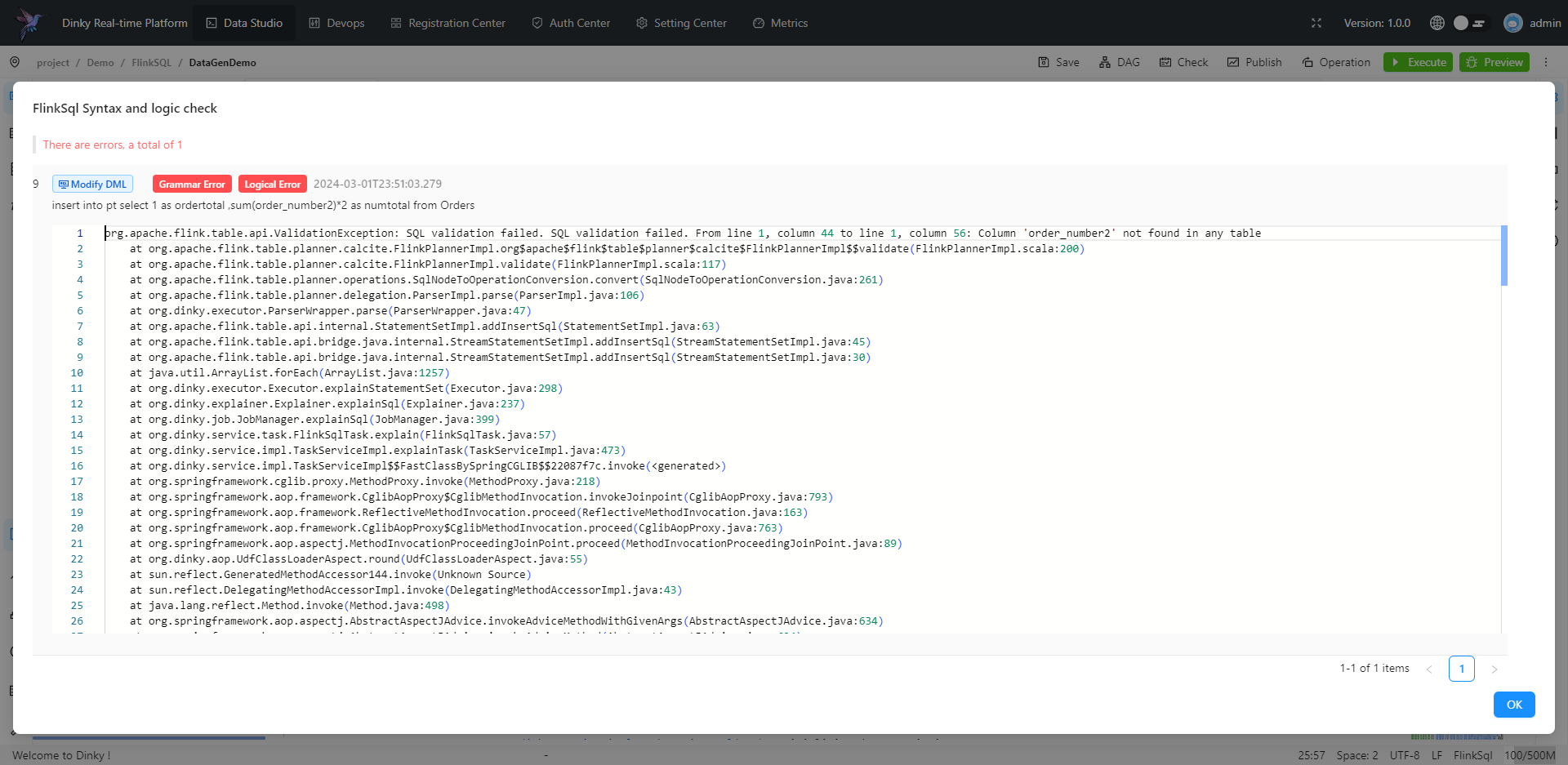
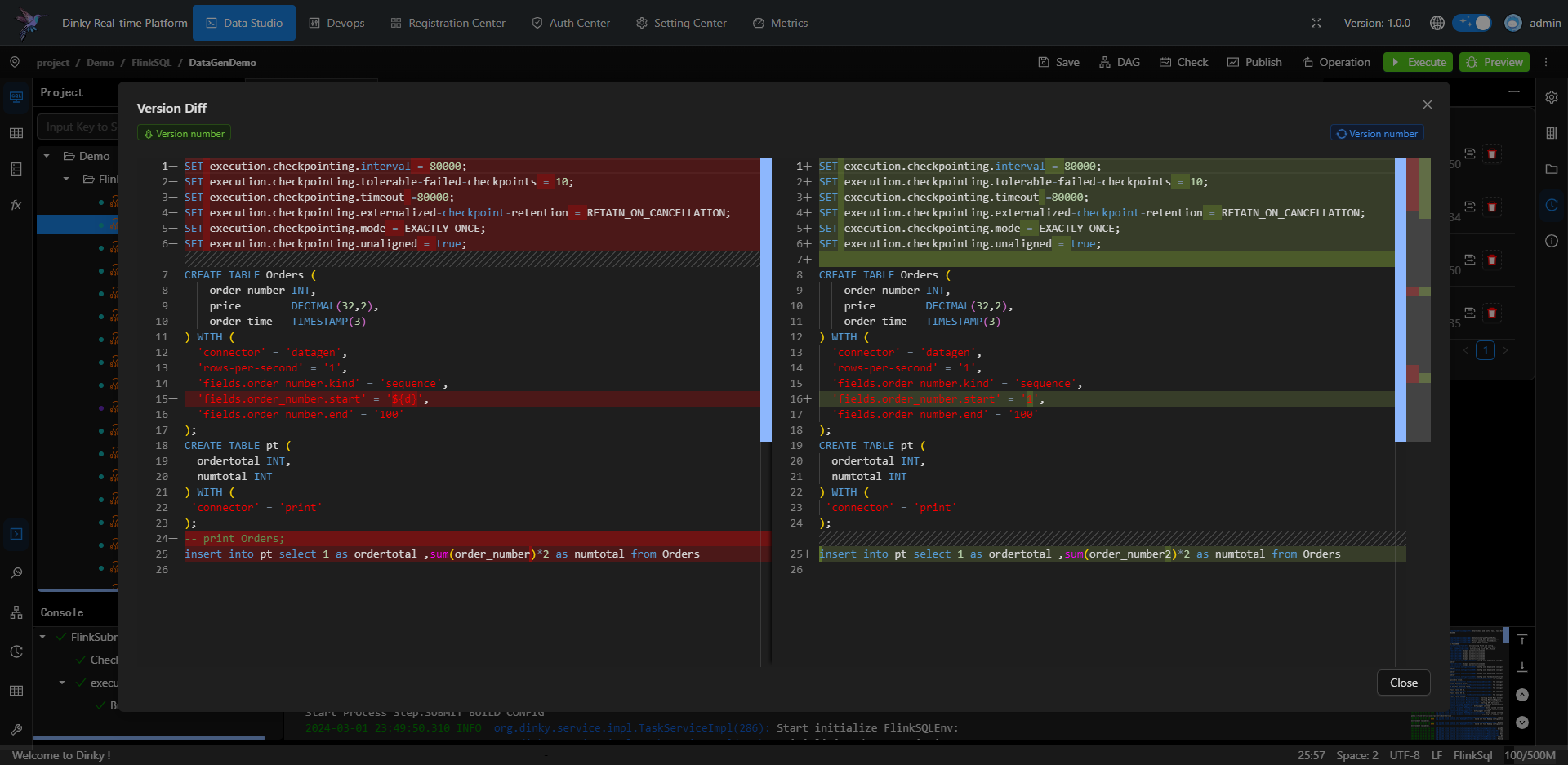
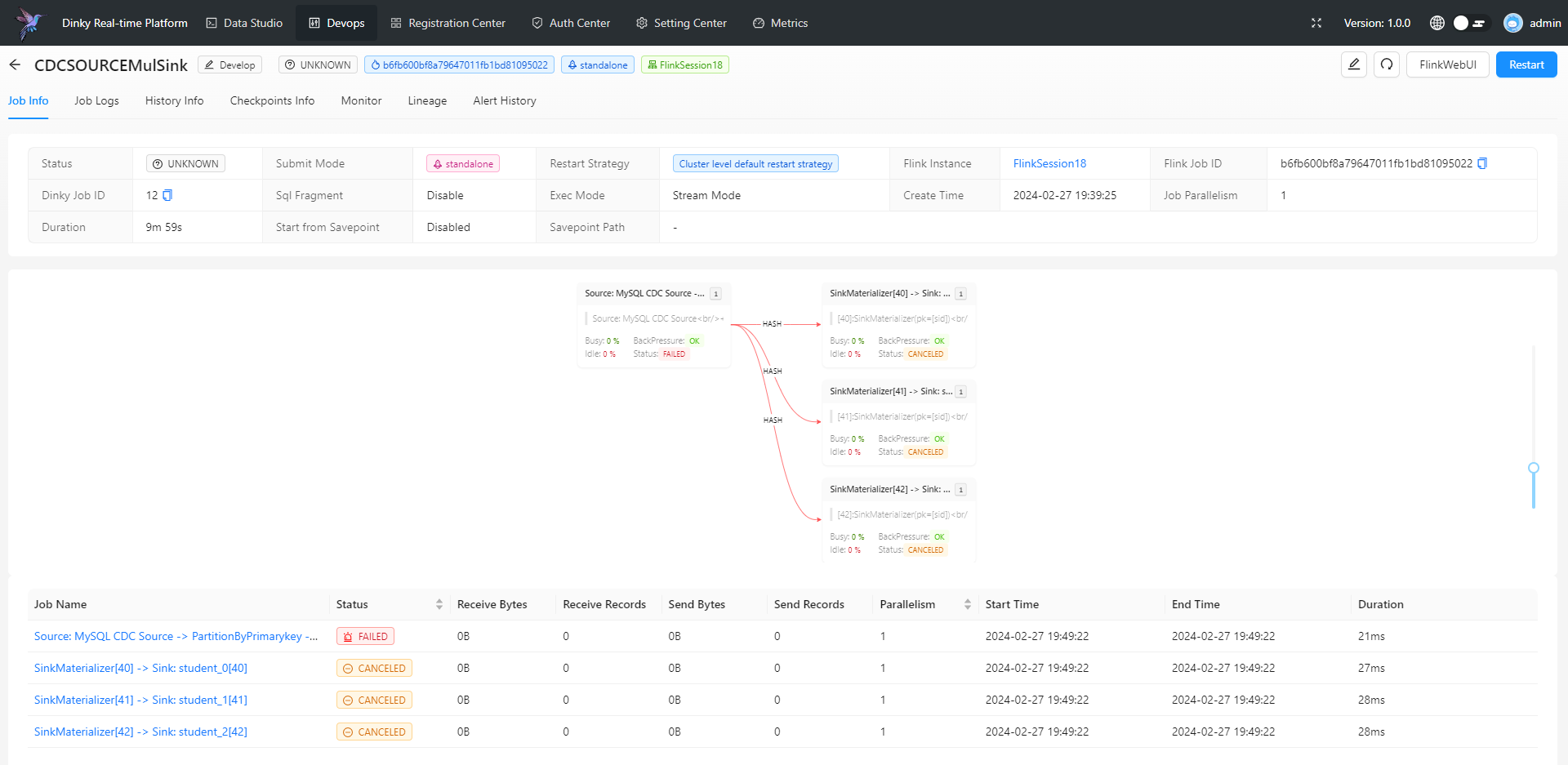
提供 FlinkSQL Studio,通过提示补全、逻辑检查、即席查询、全局变量、元数据查询等能力提升 Flink 作业开发效率
开箱即用
屏蔽技术细节,实现 Flink 所有作业提交方式,自动托管任务监控、保存点、报警等
语法增强
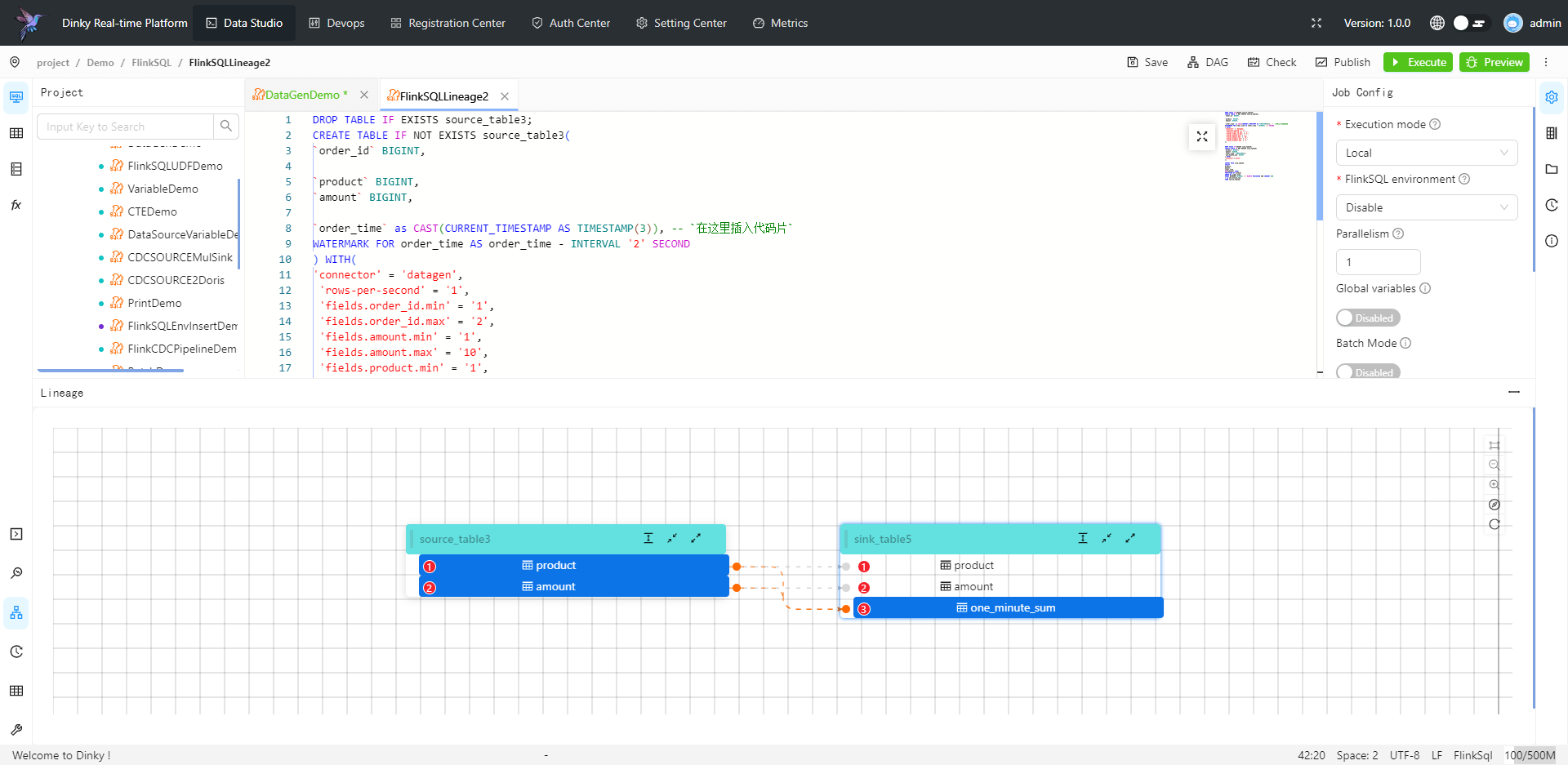
扩展 FlinkSQL 语法,如全局变量、CDC 整库同步、打印表、执行 Jar 任务等
易于扩展
多种设计模式支持快速扩展新功能,如数据源、报警方式、 CDC 整库同步、自定义语法等
无侵入性
Spring Boot 轻应用快速部署,不需要在 Flink 集群修改源码或添加额外插件,即装即用
企业推动
已有百家企业在生产环境中使用,进行实时数据开发与作业托管,大量用户实践保障项目日渐成熟